-
R Days in Rennes, France
The R Days, the annual event around R in France, was held this year in Rennes.
You can get the abstract for the talk I made around the use of AI to predict network saturation.
-
& or &&, that is the question
The R language has two AND operators:
&and&&. Knowing the difference is key when working withifclauses.The R documentation states that:
The longer form the left to right examining only the first element of each vector. Evaluation proceeds only until the result is determined. The longer form is appropriate for programming control-flow and typically preferred in if clauses.<
-
Back-up Anki with Dropbox
Anki is one of the best applications to help structure your learning with flash cards. Anki Web comes as a complement as it backs up your decks and cards on the cloud and enables to study on multiple synchronized devices (computers and phones). Anki Web has a retention period of 3 months: if you do not use the service for more than 3 months, your decks are deleted from the cloud. You end up then relying on the local version(s) on your device(s).
In this post, I wanted to share my experience to ensure a consistent and reliable back-up of the Anki decks using dropbox on Windows.
-
Rolling median with Azure Data Lake Analytics
Azure Data Lake Analytics (DLA in short) provides a rich set of analytics functions to compute an aggregate value based on a group of rows. The typical example is with the rolling average over a specific window. Below is an example where the window is centered and of size 11 (5 preceding, the current row, and 5 following). The grouping is made over the
sitefield.SELECT AVG(value) OVER(PARTITION BY site ORDER BY timestamp ROWS BETWEEN 5 PRECEDING AND 5 FOLLOWING) AS rolling_avg FROM @Data;However, the median function does not support the
ROWSoption. It is not possible therefore to run rolling median straight out of the box with DLA.PERCENTILE_DISC(0.5) WITHIN GROUP(ORDER BY value) OVER(PARTITION BY site, timestamp ROWS BETWEEN 5 PRECEDING AND 5 FOLLOWING) AS rolling_median // will generate an errorThe aim of this post is to:
- show you how the running median can be calculated on ADL by using a mix of basic
JOIN - discuss the finer points of the median functions in ADL
- compare a R implementation
- show you how the running median can be calculated on ADL by using a mix of basic
-
Custom sorting with DT
I came across a practical case a couple of days ago where the row and column ordering provided out of the box by the R DT package was not enough.
The DT package provides a wrapper around the DataTable javascript library powered by jQuery. DT can be used in Rmarkdown documents as well as in Shiny.
The goal was to display a table containing columns reporting the bandwidth consumption for some sites.
-
R Days in Anglet
The R Days took place at the end of June 2017 in Anglet, France. The slides of the various presentations have been made public on github
-
Big Data Paris 2017
The conference BigData Paris was recently organized the 6th and 7th of March 2017. I though I would share my notes regarding some of the talks I attended.
-
Load files in R with specific encoding
When working with flat files, encoding needs to be factored in right away to avoid issues down the line. UTF-8 (or UTF-16) is the de facto encoding that you hope to get. If the encoding is different, pay attention on how you load the file into R.
Let’s take the example of a file encoded as Windows-1252. Its content is displayed below using Notepad++. The editor does a pretty good job figuring out the encoding of the file. The encoding is displayed in the status bar while the
Encodingmenu enables you to change the selected character set.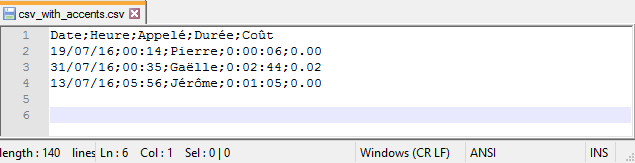
-
Foundations of Service Level Management: Book Review
I wanted to share a couple of notes I have made while reading Foundations of Service Level Management by Sturm, Morris, and Jander.
The book, written in the ’00s, deals with all the aspects of Service Level Management. More specifically, it covers topics such as measurement, how the SLA are defined, human challenges, best practices, etc.
The book is not technical at all and is overall an easy read. The first part of the book is generic to be relevant in years to come. Chapter 9 is worth a read as it covers what the customer could do before contacting a service center that delivers managed services.
-
Distinguish between a base and a SPD library
In SAS, a library engine is an engine that accesses groups of files and puts them into a logical form for processing. The engine used by default is the base engine. In addition, you may come across other engines, such as the SPD engine.
The SAS Scalable Performance Data Engine (SPD Engine) provides parallel I/O as each SAS dataset is split over multiple disks. The structure of this engine allows a faster processing of large data.
A common production set-up may define different libraries with different purposes, and therefore different engines. A library with the base engine may be used for ad-hoc reporting and small data transformation, while the library with the SPD engine may be used to store a large data mart. From a user’s perspective, the layer provided by the SAS meta-data server hides the underlying engines used by the various libraries. It is however useful to validate the type of engine being used without relying on the IT department.